|
I'm a Research Scientist at NVIDIA Research working on 3D vision, world models, telepresence, and socially intelligent robots. I was advised by Henry Fuchs during my PhD on affordable telepresence at UNC Chapel Hill. I worked with Michael Kaess on SLAM when I was in the MSCV program at CMU. I worked with Derek Hoiem on classical 3D reconstruction during my BS at UIUC and when I was at his company Reconstruct Inc.
Honors:
Industry: Reconstruct Inc. | Uber ATG | Intel Labs | NVIDIA Research
Research:
Service:
News
|

mct1224 [at] gmail.com |
|
|

|
Shengze Wang, Jiefeng Li, Tianye Li, Ye Yuan, Henry Fuchs, Koki Nagano*, Shalini De Mello*, Michael Stengel* CVPR, 2025 [Project Page] [CVPR] [Code] [Weights & File Preparation] Single-image human mesh recovery that accurately estimates perspective parameters (including Tz and focal length) from a single image, delivering SOTA pose accuracy and 2D alignment—especially for close-range views. |

|
Shengze Wang, Xueting Li, Chao Liu, Matthew Chan, Michael Stengel, Henry Fuchs, Shalini De Mello*, Koki Nagano*, CVPR, 2025 [Project Page] [CVPR] Fusion-based 3D portrait method that combines a canonical 3D prior with per-frame appearance to achieve temporally stable, identity-consistent 3D videos for single-camera telepresence. |
|
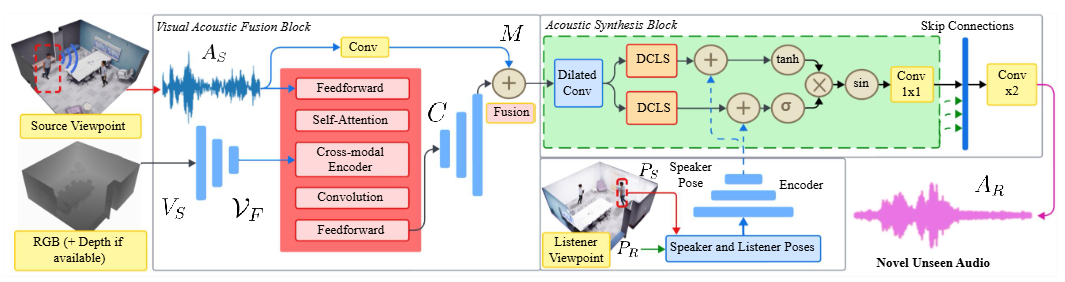
Guansen Tong, Johnathan Chi-Ho Leung, Xi Peng, Haosheng Shi, Liujie Zheng, Shengze Wang, Arryn Carlos O’Brien, Ashley Paula-Ann Neall, Grace Fei, Martim Gaspar, Praneeth Chakravarthula IEEE TVCG, 2025 [TVCG] Visual-acoustic fusion (“conformer”) + acoustic synthesis to learn scene acoustics and render spatial audio from novel viewpoints; improves immersive MR audio quality. |
|
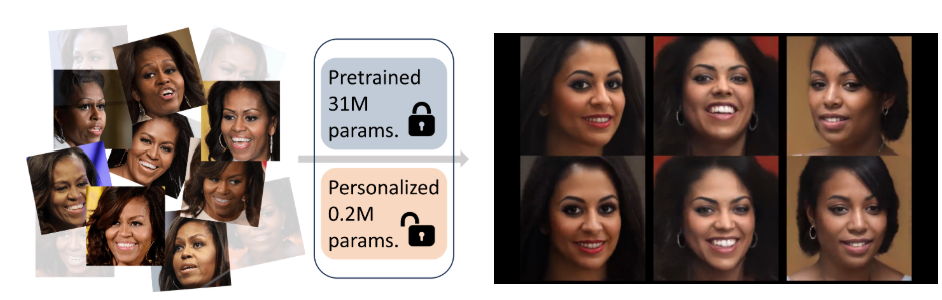
Luchao Qi, Jiaye Wu, Annie N. Wang, Shengze Wang, Roni Sengupta WACV, 2025 [Project Page] [arXiv] Personalized 3D prior of an individual using as few as 50 training images. My3DGen allows for novel view synthesis, semantic editing of a given face (e.g. adding a smile), and synthesizing novel appearances, all while preserving the original person's identity. |
|
Shengze Wang, Ziheng Wang, Ryan Schmelzle, Liuejie Zheng, YoungJoong Kwon, Roni Sengupta, Henry Fuchs IEEE TVCG, 2025 [Project Page] [arXiv] Journal version of your affordable desktop telepresence system (Bringing Telepresence to Every Desk, 2023): 4 consumer RGB-D cameras and a renderer that synthesizes high-quality free-viewpoint videos of both user and environment. |
|

|
Michael Stengel, Koki Nagano, Chao Liu, Matthew Chan, Alex Trevithick, Shalini De Mello, Jonghyun Kim, David Luebke, Amrita Mazumdar, Shengze Wang Mayoore Jaiswal SIGGRAPH Emerging Technologies, 2023 [Project Page] [NVIDIA YouTube] [ACM DL] We present an AI-mediated 3D video conferencing system that can reconstruct and autostereoscopically display a life-sized talking head using consumer-grade compute resources and minimal capture equipment. Our 3D capture uses a novel 3D lifting method that encodes a given 2D input into an efficient triplanar neural representation of the user, which can be rendered from novel viewpoints in real-time. Our AI-based techniques drastically reduce the cost for 3D capture, while providing a high-fidelity 3D representation on the receiver's end at the cost of traditional 2D video streaming. Additional advantages of our AI-based approach include the ability to accommodate both photorealistic and stylized avatars, and the ability to enable mutual eye contact in multi-directional video conferencing. We demonstrate our system using a tracked stereo display for a personal viewing experience as well as a light field display for a multi-viewer experience. |
|
Shengze Wang, Ziheng Wang, Ryan Schmelzle, Liuejie Zheng, YoungJoong Kwon, Roni Sengupta, Henry Fuchs arXiv, 2023 [Project Page][Code] We showcase a prototype personal telepresence system. With 4 RGBD cameras, it can be easily installed on every desk. Our renderer synthesizes high-quality free-viewpoint videos of the entire scene and outperforms prior neural rendering methods. |
|
|
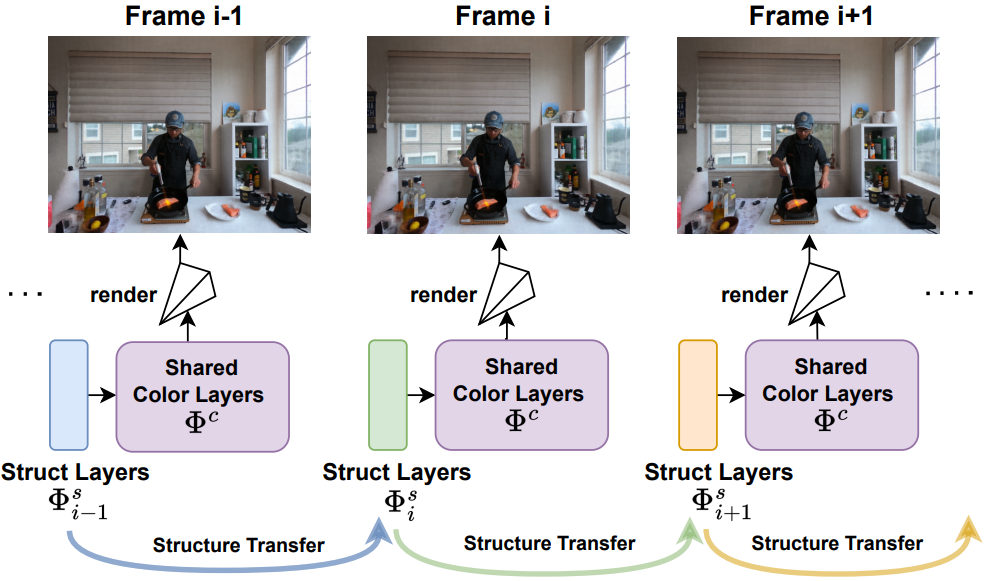
Shengze Wang, Alexey Supikov, Joshua Ratcliff, Henry Fuchs, Ronald Azuma arXiv, 2023 We discovered a natural information partition in 2D/3D MLPs, which stores structural information in early layers and color information in later layers. We leverage this property to incrementally stream dynamic free-viewpoint videos without buffering (required by prior dynamic NeRFs). With the significant reduction in training time and bandwidth, we lay foundation for live-streaming NeRF and better understanding of MLPs. |
|
Lipu Zhou, Guoquan Huang, Yinian Mao, Jincheng Yu, Shengze Wang, Michael Kaess IEEE RA-L, 2022 |
|
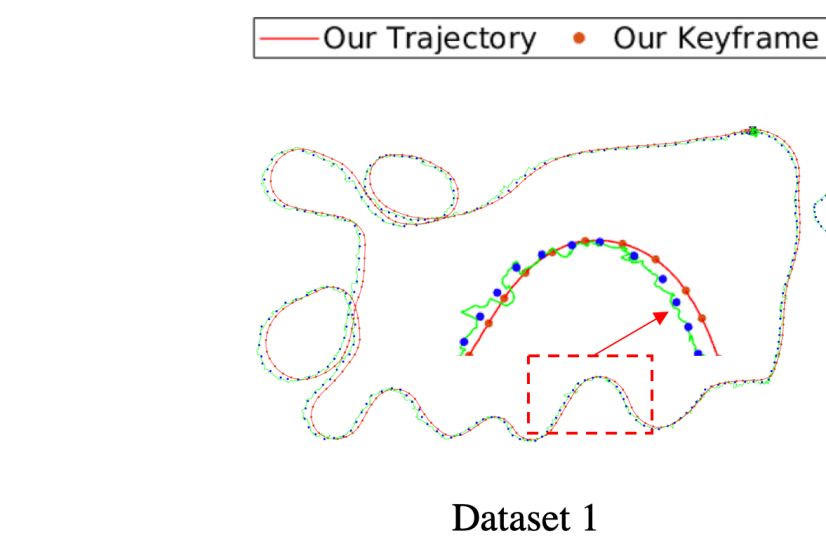
Lipu Zhou, Guoquan Huang, Yinian Mao, Shengze Wang, Michael Kaess ICRA, 2022 |

|
Shengze Wang, YoungJoong Kwon, Yuan Shen, Qian Zhang, Andrei State, Jia-Bin Huang, Henry Fuchs arXiv, 2022 We introduce a system that synthesizes dynamic free-viewpoint videos from 2 RGBD cameras. This is a preliminary work to our personal telepresence system. |

|
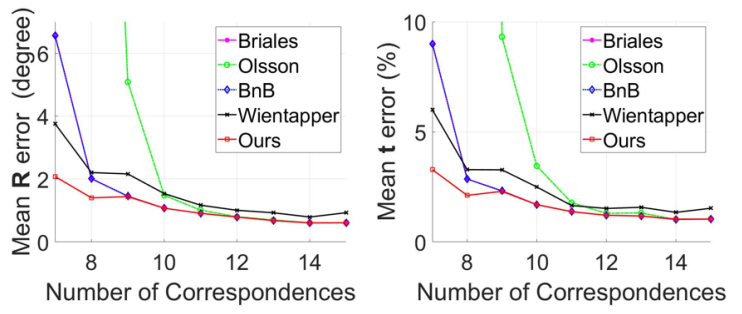
Lipu Zhou, Shengze Wang, Michael Kaess ICRA, 2021 |
|
Lipu Zhou, Shengze Wang, Michael Kaess ICRA, 2021 |
|
|
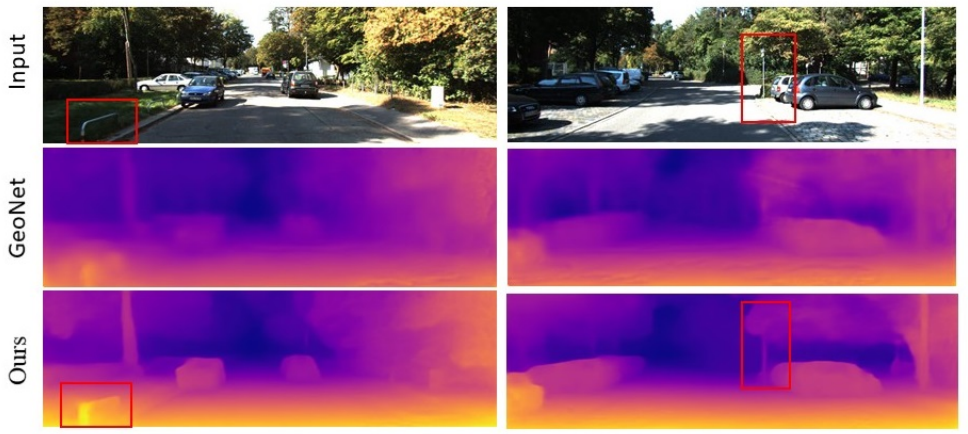
Lipu Zhou, Shengze Wang, Michael Kaess ICRA, 2020 |
|
Lipu Zhou, Shengze Wang, Jiamin Ye, Michael Kaess arXiv, 2019 |
|
Lipu Zhou, Jiamin Ye, Montiel Abello, Shengze Wang, Michael Kaess arXiv, 2018 |
|
Thank you to Jon Barron for sharing his website template with the community |