
Video Introduction (with Audio) large video (85MB)
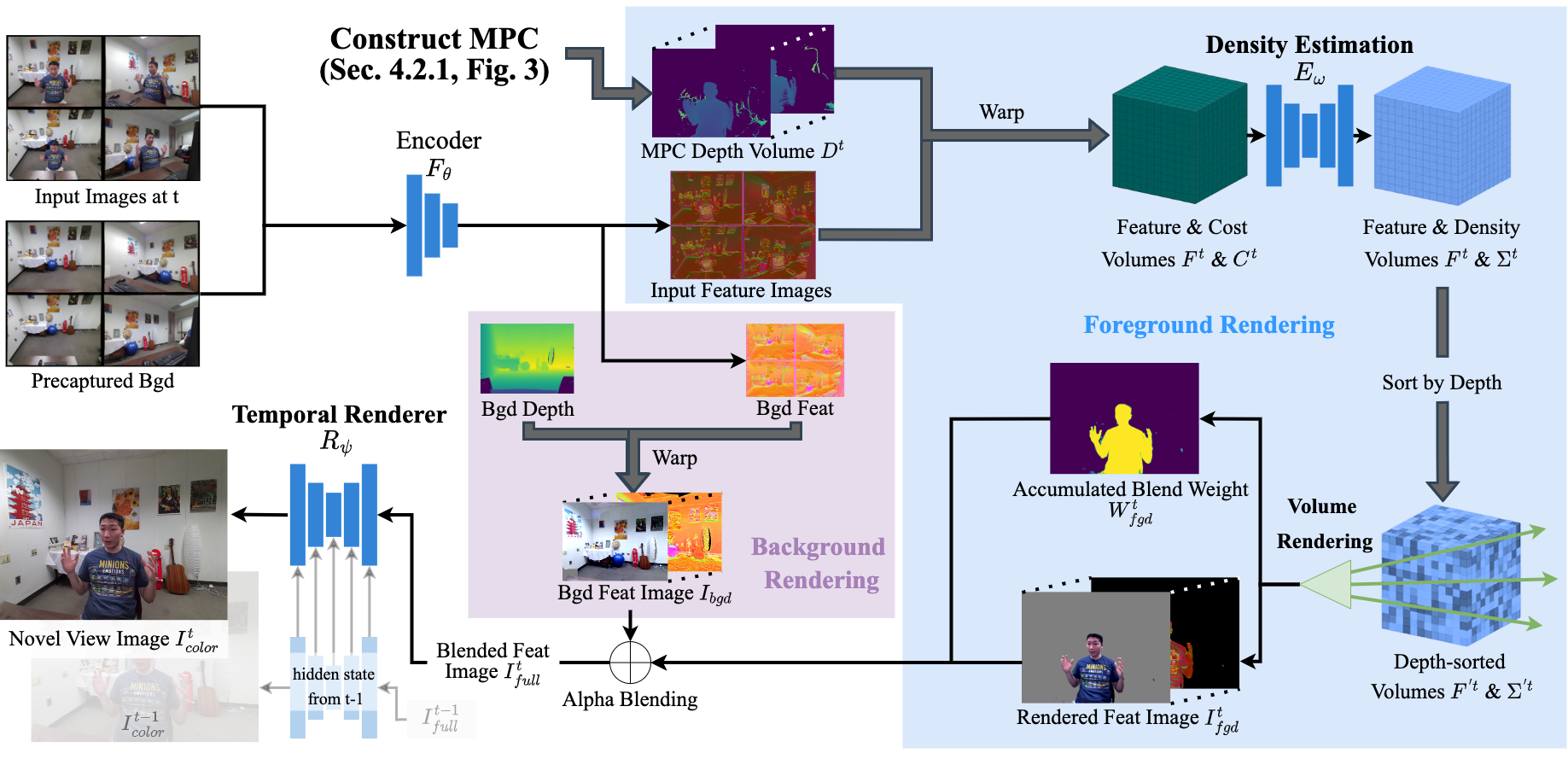
In this paper, we work to bring telepresence to every desktop. Unlike commercial systems, personal 3D video conferencing systems must render high-quality videos while remaining financially and computationally viable for the average consumer. To this end, we introduce a capturing and rendering system that only requires 4 consumer-grade RGBD cameras and synthesizes high-quality free-viewpoint videos of users as well as their environments.
Experimental results show that our system renders high-quality free-viewpoint videos without using object templates or heavy pre-processing. While not real-time, our system is fast and does not require per-video optimizations. Moreover, our system is robust to complex hand gestures and clothing, and it can generalize to new users. This work provides a strong basis for further optimization, and it will help bring telepresence to every desk in the near future. The code and dataset will be made available.

Target User (in training data), New Clothing (not in training data)
Target User (in training data), New Clothing (not in training data)
Target User (in training data), New Clothing (not in training data)
New User (not in training data)
New & Target Users
Comparisons with Microsoft VirtualCube, t-NeRF+DSNeRF, DynamicNeRF+DSNeRF, ENeRF, and ENeRF+Depth. Recent Approaches Suffer due to sparse viewpoints with wide baselines